


Count total number of Palindromic Substrings
Given a string str, find total number of possible palindromic sub-sequences. A substring need to be consecutive such that for any xixj i<j must be valid in the parent string too. Like "incl" is a substring of "includehelp" while "iel" is not.
Input:
The first line of input contains an integer T, denoting the no of test cases then T test cases follow. Each test case contains a string str.
Output:
For each test case output will be an integer denoting the total count of palindromic substring which could be formed from the string str.
Constraints:
1 <= T <= 100 1 <= length of string str <= 300
Example:
Input: test case:2 First test case: Input string: "aaaa" Output: Total count of palindromic substring is: 10 Second test case: Input string: "abaaba" Output: Total count of palindromic sub-sequence is: 11
Explanation:
Test case 1: Input: "aaaa"
The valid palindromic sub-sequences are shown below:
Marked cells are character taken in subsequence:
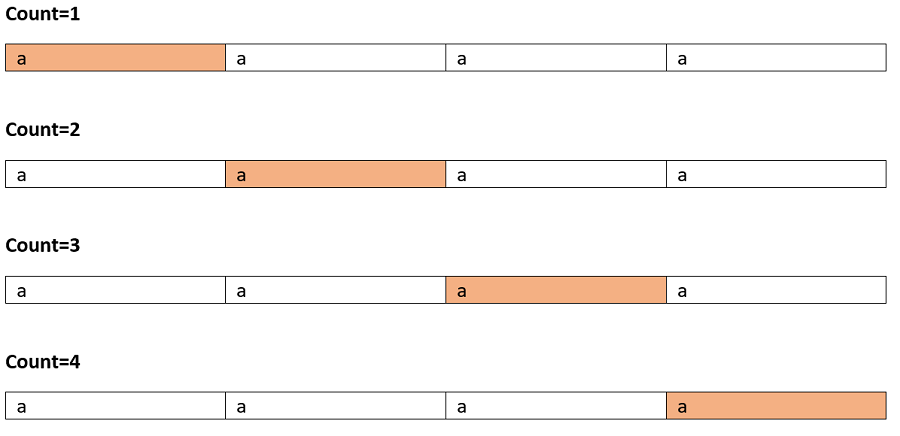
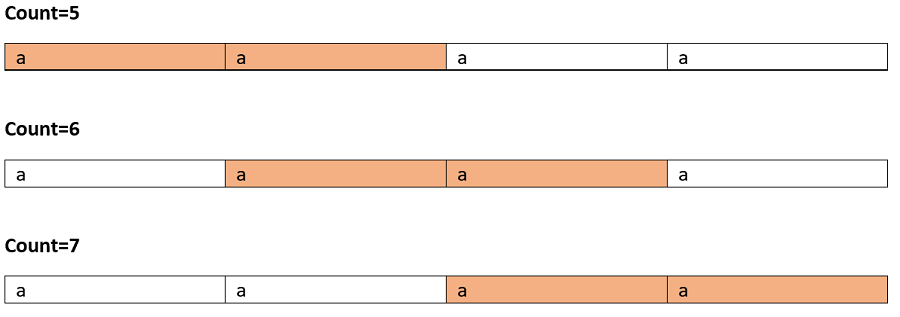
So on...
Total 10 palindromic substrings.
Actually in this case since all the character is same each and every substring is palindrome here.
For the second test case,
Few substrings can be, "a" "b" "a" "aba" So on... Total 11 such palindromic sub sequences
 C++ programming
C++ programming
This can be solved by using DP bottom up approach,
Base case is that each single character is a palindrome itself. And for length of two, i.e, if adjacent characters are found to be equal then [i][i+1]=3, pal[i][i+1]=true, else if characters are different then dp[i][i+1]=2, pal[i][i+1]=false
To understand this lets think of a string like "acaa"
Here, dp[0][1]=2 because there's only two palindrome possible because of "a" and "c".
Whereas for dp[2][3] value will be 3 as possible substrings are "a", "a", "aa".
So for higher lengths if starting and ending index is same then we recur for the remaining characters, since we have the sub-problem result stored so we computed that. In case start and end index character are different then we have added dp[start+1][end] and dp[start][end-1] that's similar to recur for leaving starting index and recur for leaving end index. But it would compute dp[start+1][end-1] twice and that why we have deducted that.
For proper understanding you can compute the table by hand for the string "aaaa" to understand how it's working.
C++ Implementation:
Output:
need an explanation for this answer? contact us directly to get an explanation for this answer