Pandas is a special tool that allows us to perform complex manipulations of data effectively and efficiently. Inside pandas, we mostly deal with a dataset in the form of DataFrame. DataFrames are 2-dimensional data structures in pandas. DataFrames consists of rows, columns, and the data.
DataFrame can be created with the help of python dictionaries or lists but in the real world, CSV files are imported and then converted into DataFrames. Sometimes, DataFrames are first written into CSV files. Here, we are going to write a DataFrame into a CSV file.
CSV files or Comma Separated Values files are plain text files but the format of CSV files is tabular. As the name suggests, in a CSV file, each specific value inside the CSV file is generally separated with a comma. The first line identifies the name of a data column. The further subsequent lines identify the values in rows.
col_1_value, col_2_value , col_3_value
row1_value1 , row_1_value2 , row_1_value3
row1_value1 , row_1_value2 , row_1_value3
Here, the separator character (,) is called the delimiter. There are some more popular delimiters. E.g.: tab(\t), colon (:), semi-colon (;) etc.
Sometimes, while reading a CSV file, we get an unnamed column which is in the form of 'Unnamed: 0'. We do not need this unwanted column hence we need to drop this column. Here, we are going to learn how to get rid of this unwanted column?



 Python programming
Python programming
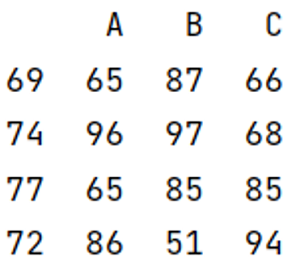
Let us understand with the help of an example,
Output:
Here, we can observe the red arrow shows that we have an unwanted column named 'unnamed:0', now we need to pass index_col=[0] which will drop this unwanted column.
Output:
need an explanation for this answer? contact us directly to get an explanation for this answer